https://www.py4e.com/lessons/tuples
https://runestone.academy/ns/books/published/py4e-int/tuples/toctree.html
https://www.keithdillon.com/index.php/python-for-data-science-spring-2026/
GitHub Classroom: https://classroom.github.com/classrooms/250035910-keithops-bds754-s26
Google CoLab: https://colab.research.google.com/notebooks/welcome.ipynb
https://docs.python.org/3/tutorial/datastructures.html
mylist = list() # or []
mylist = [1,2,3,4]
myset = set()
myset = {1,2,3,4}
mystr = str() # or ''
mystr = '1234'
mydict = dict() # or {} note similar to set
mydict = {1:'A', 2:'B', 3:11, 'hello':there}
mytuple = tuple() or () # notice can't add anything
mytuple = (1,2,3,4)
s = {1, 2, 3}
s2 = set([3, 4, 5])
s.add(4)
s.remove(2) # error if absent
s.discard(10) # no error if absent
Note this is an empty dictionary, not an empty set
X = {}
type(X)
dict
Internally a python set is a hash table (similar to dict). $O(1)$ time complexity for basic operations.
Elements must be hashable (immutable types like int, float, str, tuple, or custom objects with __hash__ dunder).
Hashable means python can generate a number representing each unique element (this is how it is easily found in $O(1)$).
t = (0,1)
dir(0)
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__getstate__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'as_integer_ratio', 'bit_count', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'is_integer', 'numerator', 'real', 'to_bytes']
ids = {1, 4, 7, 10}
measurements = {1.2, 3.5, 7.1}
languages = {"python", "c++", "rust"}
flags = {True, False}
mixed = {1, "hello", 3.14}
points = {(0,0), (1,2), (3,4)}
vowels = set("aeiou")
numbers = set(range(10))
set_of_sets = {{1,2,3}, {4,5,6}} # nope
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[11], line 1 ----> 1 set_of_sets = {{1,2,3}, {4,5,6}} TypeError: unhashable type: 'set'
dict_with_set_key = {{1,2,3}:True, {4,5,6}:False} # nope
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[13], line 1 ----> 1 dict_with_set_key = {{1,2,3}:True, {4,5,6}:False} TypeError: unhashable type: 'set'
An immutable version of a set which is hashable
set_of_sets = {frozenset({1,2,3}), frozenset({4,5,6})} # ok
set_of_sets
{frozenset({1, 2, 3}), frozenset({4, 5, 6})}
data = [3,5,5,7,7,7,9]
unique_values = set(data)
print(unique_values)
{9, 3, 5, 7}
Create a list with a repeated value in it, and convert to a set
Compute the cardinality of your set
3 in {1,2,3,4}
True
A <= B # subset
A < B # proper subset
A >= B # superset
{1,2} <= {1,2,3}
True
for x in {1,2,3,4}:
print(x)
1 2 3 4
Sets are natural in probability because probability is defined over unique outcomes
S = set(range(1,7)) # sample space: all possible outcomes
A = {2,4,6} # event A = even numbers
B = {4,5,6} # event B = numbers >=4
P_A = len(A) / len(S)
P_B = len(B) / len(S)
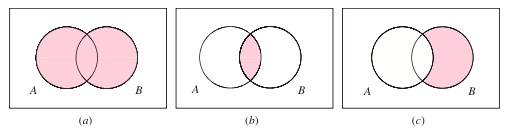
Identify A, B, their union, their intersection, that last one
What do these represent with regard to sets? What is inside the shapes? (give an example)
A = {1,2,3}
B = {3,4,5}
C = A & B # = A.intersection(B)
C
{3}
A = {1,2,3}
B = {3,4,5}
C = A | B # = A.union(B)
C
{1, 2, 3, 4, 5}
A = {1,2,3}
B = {3,4,5}
C = A - B # = A.difference(B)
C
{1, 2}
A = {1,2,3}
B = {3,4,5}
C = A ^ B
# or
C = A.symmetric_difference(B)
C
{1, 2, 4, 5}
For overlap of two clusters - ratio of common area to total area.
A = {"a","b","c","d"}
B = {"c","d","e"}
len(A & B) / len(A | B)
0.4
A |= B # union update A = A | B
A &= B # intersection update A = A & B
A -= B # difference update
A ^= B # symmetric difference update
sum()
add()
remove()
update() # update set with union of itself and other
copy() # Python "=" creates a reference not a copy for sets
Math-style iteration through an 'iterable' (list, tuple, or on-the-fly generation)
$L = \{i : i \in S\}$ --> literally {i for i in S} in python
Sets are perhaps the most direct mathematical relationship
$L = \{i : i \in S\}$ --> literally {i for i in S} in python
S = {1,2,3}
L=(i for i in S)
print(L)
for i in L:
print(i)
<generator object <genexpr> at 0x00000256545906D0> 1 2 3
S = {1,2,3}
L=(i for i in S)
print(L)
for i in L:
print(i)
<generator object <genexpr> at 0x00000256545906D0> 1 2 3
mydict = {'X':'hello', 'Y':'goodbye'}
[key for key in mydict]
['X', 'Y']
mydict = {'X':'hello', 'Y':'goodbye'}
dict((mydict[key], key) for key in mydict)
{'hello': 'X', 'goodbye': 'Y'}