Machine Learning
Keith Dillon
Fall 2018
Topic 2: Python Tools - Jupyter, Numpy/SciPy, SkLearn (and Matplotlib)
Outline: Leading Python tools:¶
Jupyter - "notebooks" for inline code + LaTex math + markup, etc.
NumPy - low-level array & matrix handling and algorithms
SciPy - higher level numerical algorithms (still fairly basic)
Matplotlib - matlab-style plotting & image display
SkLearn - (Scikit-learn) Machine Learning library
Today's lab: installing tools
Jupyter Notebooks¶
A single document containing a series of "cells". Each containing code which can be run, or images and other documentation.
- Run a cell via
[shift] + [Enter]or "play" button in the menu.

Will execute code and display result below, or render markup etc.
import datetime
print("This code is run right now (" + str(datetime.datetime.now()) + ")")
'hi'
1+2+2
Installation¶
First project: get Jupyter running and be able to import listed tools
Easiest to install via Anaconda. Preferrably Python 3.
conda install numpy scipy scikit-learn jupyter matplotlib
Many other packages. E.g. pandas.
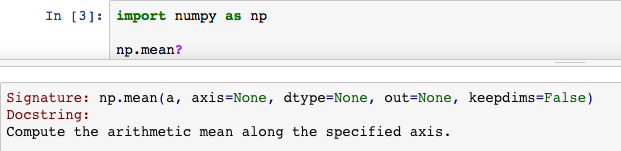
Python Help Tips¶
- Get help on a function or object via
[shift] + [tab]after the opening parenthesisfunction(
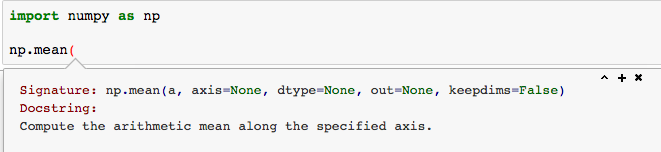
- Can also get help by executing
function?
NumPy¶
Numerical algorithm toolbox, similar to Matlab. Many key differences, such as zero-based indexing (like C) instead of one-based (like math texts).
Arrays - special data structure which allows direct and efficient linear algebra manipulations.
import numpy as np
x = np.array([2,0,1,8])
print(x)
Fast Numerical Mathematics¶
l = range(1000)
%timeit [i ** 2 for i in l]
import numpy as np
a = np.arange(1000)
%timeit a ** 2
NumPy for Matlab Users¶
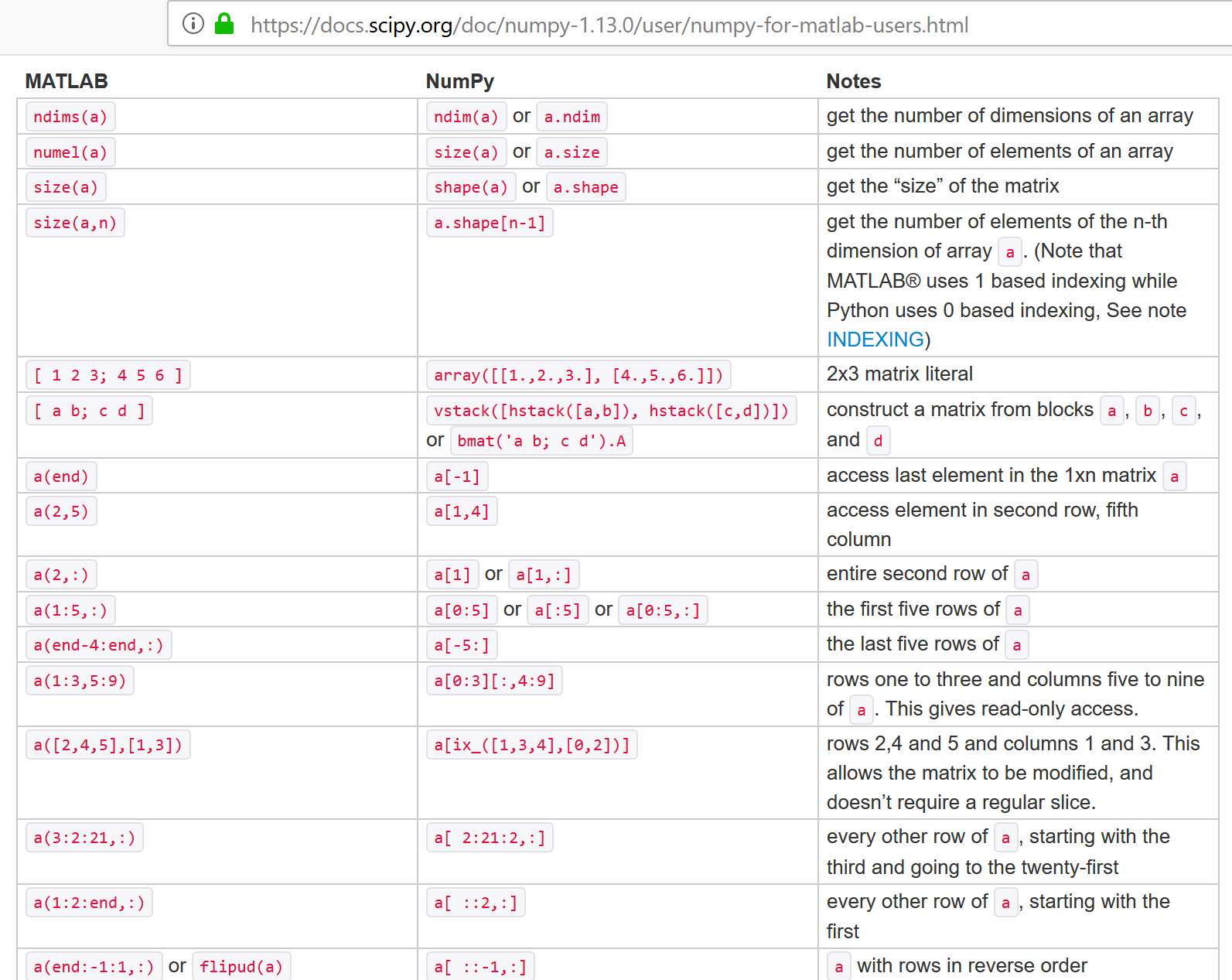
help(np.array)
Will cover more next class
SciPy¶
Implements higher-level scientific algorithms using NumPy. Examples:
- Integration (scipy.integrate)
- Optimization (scipy.optimize)
- Interpolation (scipy.interpolate)
- Signal Processing (scipy.signal)
- Linear Algebra (scipy.linalg)
- Statistics (scipy.stats)
- File IO (scipy.io)
import scipy
dir(scipy)
Matplotlib¶
Tutorial from: https://github.com/amueller/scipy-2017-sklearn/blob/master/notebooks/02.Scientific_Computing_Tools_in_Python.ipynb
Another important part of machine learning is the visualization of data. The most common
tool for this in Python is matplotlib. It is an extremely flexible package, and
we will go over some basics here.
Jupyter hass built-in "magic functions", the "matoplotlib inline" mode, which will draw the plots directly inside the notebook. Should be on by default.
%matplotlib inline
import matplotlib.pyplot as plt
# Plotting a line
x = np.linspace(0, 10, 100)
plt.plot(x, np.sin(x));

# Scatter-plot points
x = np.random.normal(size=500)
y = np.random.normal(size=500)
plt.scatter(x, y);

# Showing images using imshow
# - note that origin is at the top-left by default!
x = np.linspace(1, 12, 100)
y = x[:, np.newaxis]
im = y * np.sin(x) * np.cos(y)
print(im.shape)
plt.imshow(im);

# Contour plots
# - note that origin here is at the bottom-left by default!
plt.contour(im);

# 3D plotting
from mpl_toolkits.mplot3d import Axes3D
ax = plt.axes(projection='3d')
xgrid, ygrid = np.meshgrid(x, y.ravel())
ax.plot_surface(xgrid, ygrid, im, cmap=plt.cm.viridis, cstride=2, rstride=2, linewidth=0);

There are many more plot types available. See matplotlib gallery.
Test these examples: copy the Source Code
link, and put it in a notebook using the %load magic.
For example:
# %load http://matplotlib.org/mpl_examples/pylab_examples/ellipse_collection.py
SkLearn¶
Considered leading Machine Learning toolbox.
Many Machine Learning functions.
Couple dozen core developers + hundreds of other contributors.
2011 tutorial has over 10,000 citations.
"Scikit-learn: Machine Learning in Python", Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, Édouard Duchesnay; 12(Oct):2825−2830, 2011
import sklearn as sk
dir(sk)
API Reference¶
In this class:¶
We will emphasize the use of these tools to run algorithms rather than on ability to derive and code methods (which would require significantly more prerequisite abilities).
We will focus on the key issues in using machine learning methods in practical applications, such as loading data, preprocessing, validation, and determining which method to use.