Unstructured Data & Natural Language Processing
Keith Dillon
Spring 2020
Topic 10: Sequence-to-Sequence networks
This topic:¶
- seq2seq
- Sequence optimality
- Applications
Reading:¶
- J&M Chapter 10 (Encoder-Decoder Models, Attention, and Contextual Em-beddings)
- Young et al, "Recent trends in deep learning based natural language processing" 2018
- Sebastian Ruder, "A Review of the Neural History of Natural Language Processing" 2018
Sequence-to-sequence models¶
Sutskever et al 2014: sequence-to-sequence learning
A general framework for mapping one sequence to another one using a neural network
- Encoder network process a sentence symbol-by-symbol, produces a vector representation
- Decoder network predicts the output symbol-by-symbol based on the encoder state
Machine Translation (MT)¶
- the task of automatically translating sentences from one language (source) into another (target)
- Labeled data = parallel texts, a.k.a. or bitexts. large text collections consisting of pairs of sentences from different languages that are translations of one another.
seq2seq for Machine Translation¶
- Google replaced monolithic phrase-based MT models with neural MT models in 2016 (Wu et al., 2016)
- "now the go-to framework for natural language generation tasks" - Sebastian Ruder in 2018
- Various approaches to encoder & decoder networks
III. Encoder-decoder Models¶
Transduction — input sequences transformed into output sequences in a one-to-one fashion.
E.g. signal (energy) transduction from electricity to sound and vice versa - transducer
Encoder-decoder networks,¶
- A.k.a. sequence-to-sequence models
- capable of generating contextually appropriate, arbitrary length, output sequences.
- Have been applied to a very wide range of applications including...
- machine translation
- summarization
- question answering
- dialogue modeling.
Key idea¶
- an encoder network that takes an input sequence and creates a contextualized representation of it.
- This representation is then passed to a decoderwhich generates a task-specific output sequence.
- The encoder and decoder networks are typically implemented with the same architecture, often using recurrent networks
- Trained in an end-to-end fashion for each application
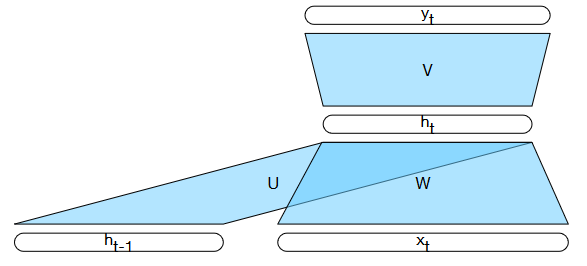
Recall RNN¶
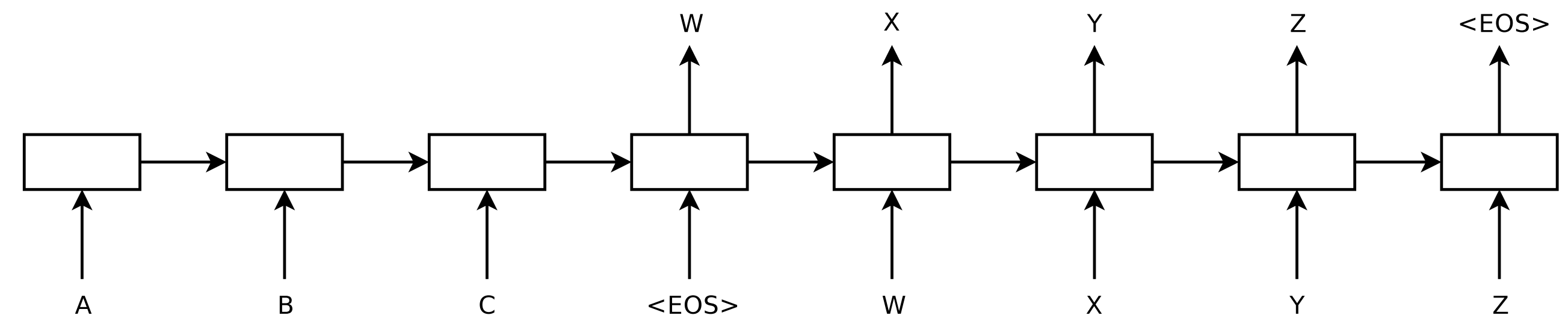
MT using Language model¶
- An early approach
- concatenate source and target sentences into single sequence
- with end of sentence marker in between - also predict when sentence translation ends
- Train as autoregressive modelling
- Use entire source sentence as prefix
- Apply RNN to generate dist over possible next words (softmax values)
- Choose word from dist (e.g. max likelihood)
- Feed word back in as next input (autoregressive) -- but use certain length "prefix" first
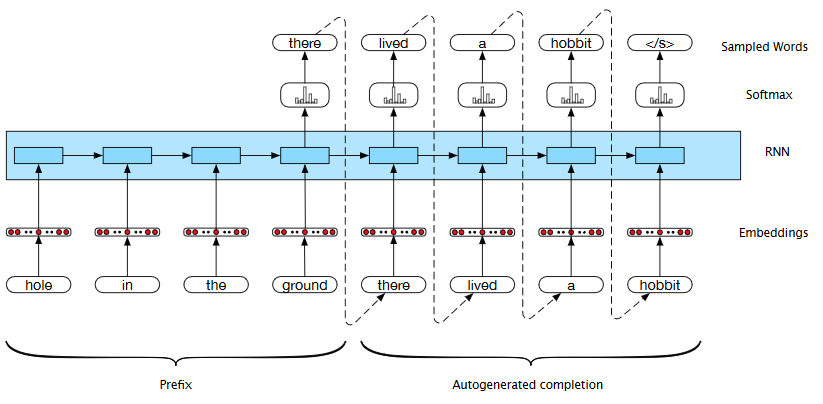
Recall must embed word when chosen for feedback
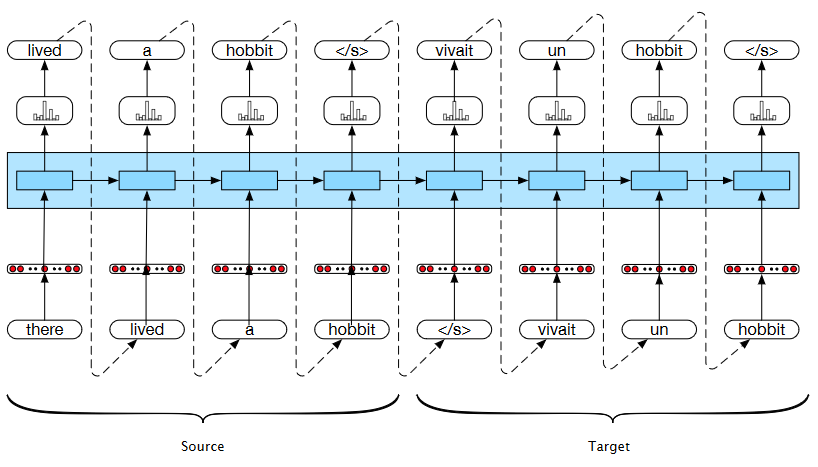
Encoder-Decoder Network - Simple initial architecture:¶
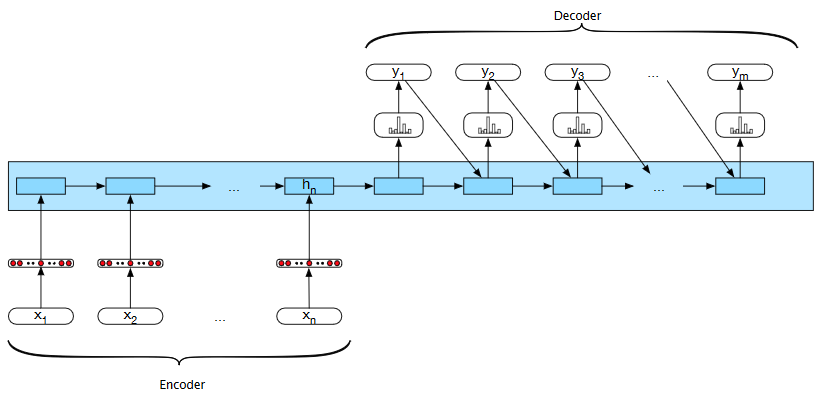
Basic RNN-based encoder-decoder architecture. The final hidden state of the encoder RNN serves as the context for the decoder in its role as $h_0$ in the decoder RNN
Encoder-Decoder Network - General architecture:¶
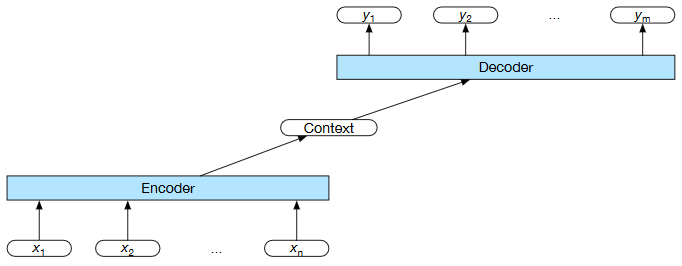
- encoder and decoder can be different networks
- context is a function of the vector of contextualized input representations and may be used by the decoder in a variety of ways
Encoder¶
- Can use simple RNNs, LSTMs, GRUs, convolutional networks, as well as transformer net-works (covered later)
- Stacked architectures are the norm - a stack of Bi-LSTMs common
- Output result for final hidden layer after $n$th input $\mathbf h_n^e$.
Encoder Networks¶
Typically RNN's
Other:
- Deep LSTMs (Wu et al 2016)
- Convolutional encoders (Kalchbrenner et al., 2016; Gehring et al 2017)
- Transformer (Vaswani et al 2017)
- Combined LSTM and Transformer (Chen et al 2018)
Context¶
- takes final hidden state of encoder as input $\mathbf h_n^e$
- simplest idea - just pass it along to decoder as context $\mathbf c = \mathbf h_n^e$
Decoder¶
- Again use LSTMs or GRUs, in stacked architecture
- Feedback states initialized with context $\mathbf h_0^{(d)} = c$ (rather than e.g. zeros)
- Recursive decoder based on prior outputs and prior states only $\mathbf h_t^{(d)} = g(\hat{y}_{t-1},\mathbf h_{t-1}^{(d)})$
- Network output is function of $\mathbf h_t^{(d)}$, e.g. softmax
- improvement: rather than only using context for initialization, may continue passing it as a "carry" term $$\mathbf h_t^{(d)} = g(\hat{y}_{t-1},\mathbf h_{t-1}^{(d)},c)$$
II. Sequence Optimality Problem¶
Greedy versus Global Optimal¶
- Greedily choosing decoder outputs -- at any step in sequence can pick most likely individual output -- may produce a sequence of most-likely outputs may not be very likely at all (e.g. "the the the")
- Want way of preferentially getting likely sequences, as done with Markov models
- Dynamic programming tricks to make this practical (like Viterbi decoding) can't be easily done here due to recurrent feedback of chosen outputs -- output distributions vary depending on prior sequence
Beam Search¶
- View the decoding problem as a heuristic state-space search and systematically explore the space of possible outputs
- Combin breadth-first-search strategy with a heuristic filter that scores each option and prunes the search space to stay within a fixed-size memory footprint
- this memory size constraint is called the beam width $B$
- At the first step of decoding, we select the $B$ best options from the softmax output $y$
- Each option is scored with its correspondingprobability from the softmax output of the decoder.
- At subsequent steps, each hypothesis is extended incrementally by being passed to distinct decoders (along with context and prior hidden states), which again generate a softmax over the entire vocabulary.
- score subsequent hypotheses based on both word likelihood and likelihood of entire sequence thus far, discard all but top $B$ likely hypotheses
- may need to normalize for sequence length differences when comparing
III. Applications Beyond Translation¶
Neural Chatbot¶
- JM Chapter 24 (Dialog Systems and Chatbots), 24.1.2 - sequence to sequence chatbots
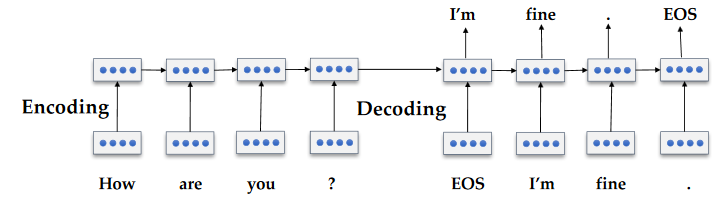
Adaptation of machine translation technique
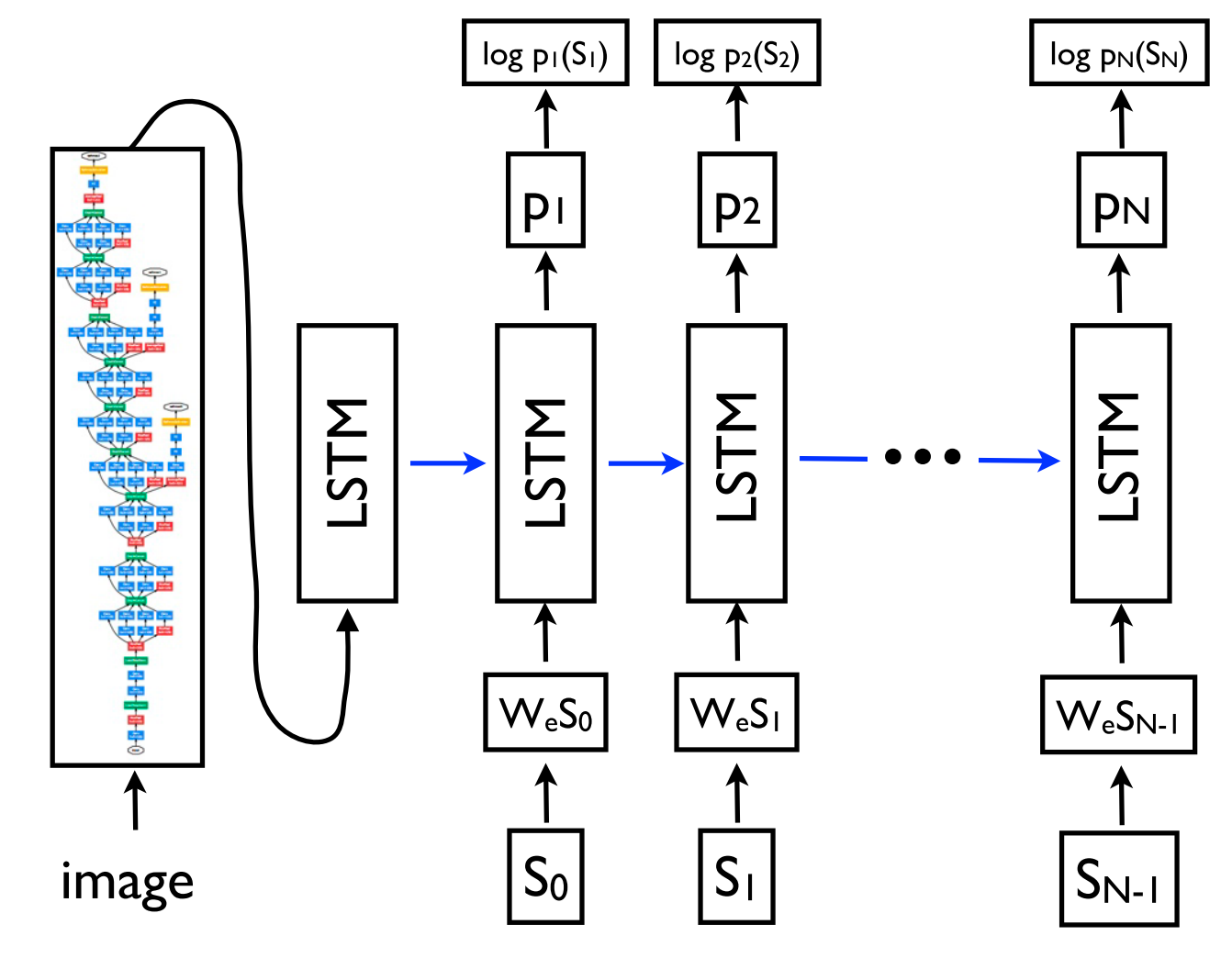
Code2text¶
- Loyola et al 2017, "A Neural Architecture for Generating Natural Language Descriptions from Source Code Changes"
- automatically describe changes introduced in the source code of a program
- Train from dataset of code-commits, which contains both the modifications and message introduced by an user
Table2text¶
Lebret et al 2016, "Neural Text Generation from Structured Data with Application to the Biography Domain"
Input = fact tables, fact-table2vec embedding
Output = biographical sentences

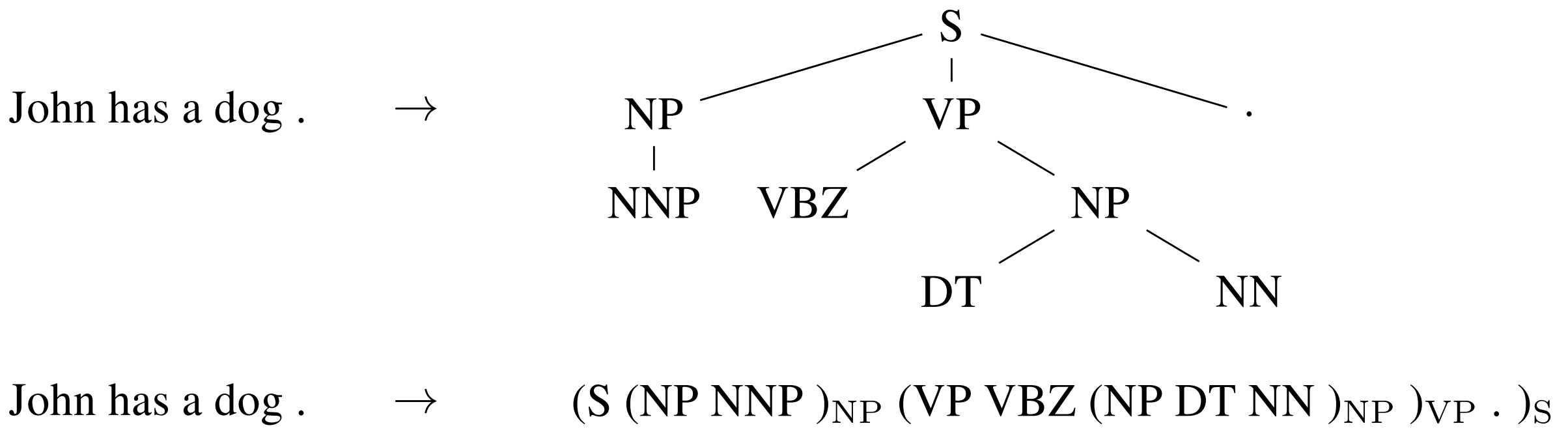
Text2Grammar: Grammatical parsing¶
Vinyals et al 2015, "Grammar as a Foreign Language"
Convert parsing tree into a sequence, "linearizing the structure"
byte2span: Automated annotation¶
- Gillick et al 2016, "Multilingual Language Processing From Bytes"
- Reads text as bytes and outputs span annotations [start, length, label]
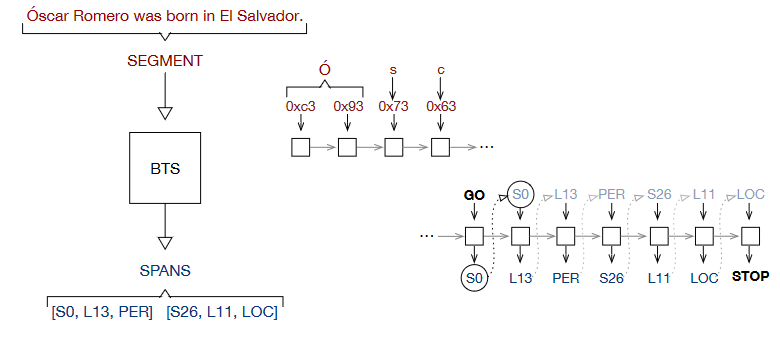
GO = "generate output" input
Use for Entity Recognition (NER), Semantic Role Labeling, other tasks