This topic:¶
- Motivation
- Calculus for optimizing neural networks
- Gradient Descent and its Variations
- Autodiff for computing the gradient
Reading:
- Chollet: Chapter 2
- GBC: Chapter 5.9, 6, 8
- "An overview of gradient descent optimization algorithms", Sebastian Ruder , 2017, https://arxiv.org/abs/1609.04747
- https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
- https://www.youtube.com/watch?v=q0pm3BrIUFo
0. Motivation¶
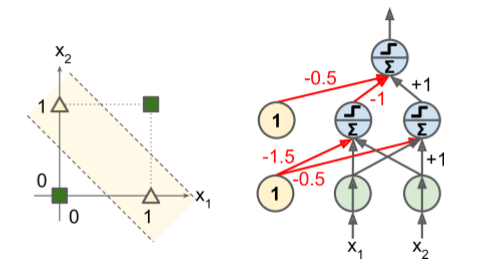
Problem: Non-linear Decision Boundaries¶
"Perceptrons", Marvin Minsky and Seymour Papert 1969
- highlighted a number of serious weaknesses of Perceptrons, in particular the fact that they are incapable of solving some trivial problems (e.g., the Exclusive OR (XOR) classification problem).
- true of any other linear classification model as well such as Logistic Regression classifiers),
- researchers had expected much more from Perceptrons, and their disappointment was great
- as a result, many researchers dropped connectionism altogether (i.e., the study of neural networks) in favor of higher-level problems such as logic, problem solving, and search.
Solution: Multilayer Perceptrons (LP)¶
- Some of the limitations of Perceptrons can be eliminated by stacking multiple Perceptrons.
- feed-forward: one-way flow of information
- The resulting ANN is called a Multi-Layer Perceptron (MLP)
- In particular, an MLP can solve the XOR problem
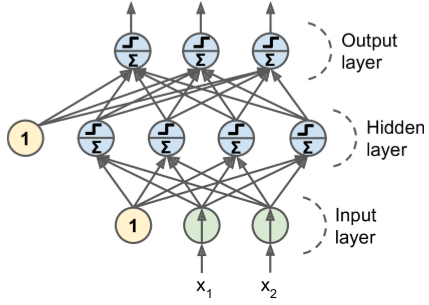
MLP Layers¶
An MLP is composed of
- one (passthrough) input layer,
- one or more layers of LTUs, called hidden layers,
- one final layer of LTUs called the output layer
Every layer except the output layer includes a bias neuron and is fully connected to the next layer.
When an ANN has two or more hidden layers, it is called a deep neural network (DNN).
Perceptron training algorithm doesn't extend to MLP's.
No good training algorithm for many years.
Backpropagation¶
- “Learning Internal Representations by Error Propagation,” D. E. Rumelhart et al 1986, a groundbreaking article introducing the backpropagation training algorithm (also independently discovered by others)
- Today we would describe it as Gradient Descent using reverse-mode autodiff
For each training instance¶
- the algorithm feeds it to the network and computes the output of every neuron in each consecutive layer (this is the forward pass, just like when making predictions).
- Then it measures the network’s output error (i.e., the difference between the desired output and the actual output of the network),
- and it computes how much each neuron in the last hidden layer contributed to each output neuron’s error.
- It then proceeds to measure how much of these error contributions came from each neuron in the previous hidden layer—and so on until the algorithm reaches the input layer.
This reverse pass efficiently measures the error gradient across all the connection weights in the network by propagating the error gradient backward in the network (hence the name of the algorithm).
Key change to the MLP’s architecture: replace the step function with the logistic function,
$$ σ(z) = \frac{1}{1 + \exp(–z)}. $$
Needed for there to be gradients to work with (else they are all zero or infinity)
Other workable activation functions
- tanh
- ReLU
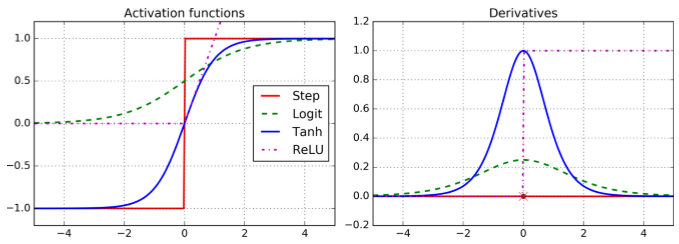
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def relu(z):
return np.maximum(0, z)
def derivative(f, z, eps=0.000001):
return (f(z + eps) - f(z - eps))/(2 * eps)
z = np.linspace(-5, 5, 200)
plt.figure(figsize=(11,4))
plt.subplot(121)
plt.plot(z, np.sign(z), "r-", linewidth=1, label="Step")
plt.plot(z, sigmoid(z), "g--", linewidth=2, label="Sigmoid")
plt.plot(z, np.tanh(z), "b-", linewidth=2, label="Tanh")
plt.plot(z, relu(z), "m-.", linewidth=2, label="ReLU")
plt.grid(True)
plt.legend(loc="center right", fontsize=14)
plt.title("Activation functions", fontsize=14)
plt.axis([-5, 5, -1.2, 1.2])
plt.subplot(122)
plt.plot(z, derivative(np.sign, z), "r-", linewidth=1, label="Step")
plt.plot(0, 0, "ro", markersize=5)
plt.plot(0, 0, "rx", markersize=10)
plt.plot(z, derivative(sigmoid, z), "g--", linewidth=2, label="Sigmoid")
plt.plot(z, derivative(np.tanh, z), "b-", linewidth=2, label="Tanh")
plt.plot(z, derivative(relu, z), "m-.", linewidth=2, label="ReLU")
plt.grid(True)
#plt.legend(loc="center right", fontsize=14)
plt.title("Derivatives", fontsize=14)
plt.axis([-5, 5, -0.2, 1.2])
plt.show()

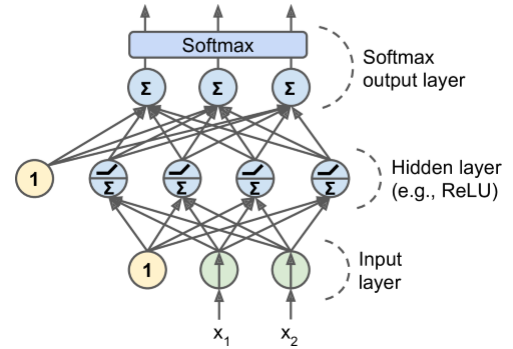
Activation Functions for Classification¶
for classification each output corresponds to a different binary class (e.g., spam/ham, urgent/not-urgent, and so on).
Potential for multiple classes chosen at same time
When the classes are exclusive (e.g., classes 0 through 9 for digit image classification), the output layer is typically modified by replacing the individual activation functions by a shared softmax function
I. Calculus for Optimizing Neural Networks¶
The Rise of Calculus¶
People are now making billions of dollars using derivatives from High School calculus.

Technically Calc III
Remembering Calculus Class¶
Finding max or min by setting derivative equal to zero
Gradient descent for minimizing function
Find location and value of minimum of $J(w) = w^2 - 2w + 5$.
Solve this using gradient descent manually starting from $w=0$
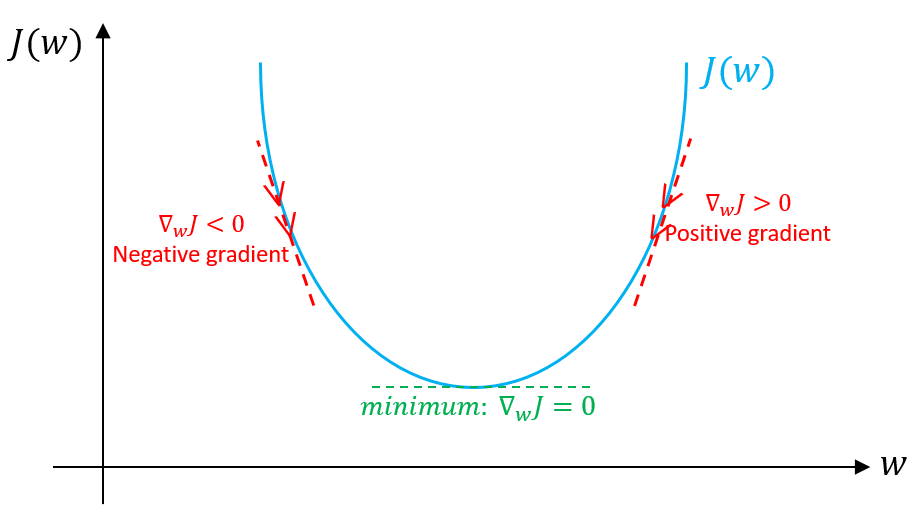
"$J$" denotes the objective function, meaning the thing optimized. We pick what $J$ is based on our goal.
Matrix Calculus¶
Multidimensional derivatives (gradients) via linear algebra
https://en.wikipedia.org/wiki/Matrix_calculus
https://www.math.uwaterloo.ca/~hwolkowi/matrixcookbook.pdf
"The Matrix Calculus You Need For Deep Learning" https://arxiv.org/abs/1802.01528
Example¶
Suppose we want to compute the gradients of the function $f(x,y)=x^2y + y + 2$ with regards to the parameters x and y:
def f(x,y):
return x*x*y + y + 2
Solve analytically¶
$\dfrac{\partial f}{\partial x} = 2xy$
$\dfrac{\partial f}{\partial y} = x^2 + 1$
E.g. $\dfrac{\partial f}{\partial x}(3,4) = 24$ and $\dfrac{\partial f}{\partial y}(3,4) = 10$.
def df(x,y):
return 2*x*y, x*x + 1
df(3, 4)
Equations for the second order derivatives (also called Hessians):¶
$\dfrac{\partial^2 f}{\partial x \partial x} = \dfrac{\partial (2xy)}{\partial x} = 2y$
$\dfrac{\partial^2 f}{\partial x \partial y} = \dfrac{\partial (2xy)}{\partial y} = 2x$
$\dfrac{\partial^2 f}{\partial y \partial x} = \dfrac{\partial (x^2 + 1)}{\partial x} = 2x$
$\dfrac{\partial^2 f}{\partial y \partial y} = \dfrac{\partial (x^2 + 1)}{\partial y} = 0$
At x=3 and y=4, these Hessians are respectively 8, 6, 6, 0. Let's use the equations above to compute them:
def d2f(x, y):
return [2*y, 2*x], [2*x, 0]
d2f(3, 4)
Calculus for Optimization¶
With calculus we can find the (local) minimum or maximum of some function.
How do we use this in a learning algorithm?
Minimize a Loss function (or Cost function, or Risk functon) "$L$" $\rightarrow$ $J$
Basically a metric which tells how well our function predicts the true labels for a sample.
$$f(\mathbf x) \approx y$$
How might we quantify the performance here?
Loss functions¶
- Squared loss: for $y \in \mathbf R$, used for predicting real outputs, but can use for anything.
$$L(f(\mathbf x),y) = (f(\mathbf x) - y)^2$$
- Logistic loss: for $y \in \{-1,+1\}$, used for predicting binary outputs ~ so for classification.
$$L(f(\mathbf x),y) = \log\{1+\exp[y f(\mathbf x)]\}$$
Both are smooth so good for gradient descent.
Empirical Loss¶
Consider e.g., squared loss: $L(f(\mathbf x),y) = (f(\mathbf x) - y)^2$, for $y \in \mathbf R$
Note this is just using one sample. We are comparing the output of the network to the true label (a.k.a. target).
As before we want to use an entire set of data ("training data") to optimize our weights. We call the net loss over all of it the empirical loss.
$$ L_{emp}(f) = \frac{1}{m}\sum_{i=1}^m L\big(f(\mathbf x_{(i)}), y_i\big) $$
So we just sum over all the samples.
Sigmoid Activation Function¶
You may have noticed a problem with the loss not changing when you adjust the weights a small amount. This is a general problem with the step function used in the perceptron. Instead try a sigmoid activation function or a ReLU activation function.
$$\text{Sigmoid}(z) = \frac{1}{1+e^{-z}}$$
$$ \text{ReLU}(z) = \alpha \max(0,z)= \begin{cases} 0, \text{ if } z < 0 \\ \alpha z, \text{ if } z > 0 \end{cases} $$
Sigmoid Activation Function¶
z = np.arange(-10, 10, 0.1)
plt.plot(z, 1 / (1 + np.exp(-z)), linewidth=3);
plt.xlabel('z');
plt.ylabel('sigma(z)');

Scavenger Hunt¶
Find the derivative of the sigmoid($z$) wrt $z$
Rectified Linear Unit¶
$$ \text{ReLU}(z) = \alpha \max(0,z)= \begin{cases} 0, \text{ if } z < 0 \\ \alpha z, \text{ if } z > 0 \end{cases} $$
The activation function that was popular when Deep Learning became famous.
Not smooth but gradient still simple to do computationally.
Variants such as "Leaky ReLU" improve implementation details.
z = np.arange(-10, 10, 0.1)
plt.plot(z, [max(0, i) for i in z], linewidth=3);
plt.xlabel('z');
plt.ylabel('ReLU(z)');

Exercise¶
Compute derivative of ReLU($z$) wrt $z$ (for as many points as you can)
$$ \text{ReLU}(z) = \alpha \max(0,z)= \begin{cases} 0, \text{ if } z < 0 \\ \alpha z, \text{ if } z > 0 \end{cases} $$
Hint: derivative will have multiple cases too.
Optimization with Gradients¶
Instead of using tiny steps, we use derivatives which we compute analytically.
$$ J'(w) = \lim_{d\rightarrow 0} \frac{J(w+d)-J(w)}{d}$$
The partial derivative means just focus on one variable at a time:
$$ \frac{\partial}{\partial w_1}J(w_1, w_2, w_3) = \lim_{d\rightarrow 0} \frac{J(w_1+d,w_2,w_3)-J(w_1,w_2,w_3)}{d}$$
Compute these partial derivatives for each weight and stick result in a vector, and you have the gradient:
$$\nabla J(w_1, w_2, w_3) = \begin{pmatrix}\frac{\partial}{\partial w_1}J(w_1, w_2, w_3),\frac{\partial}{\partial w_2}J(w_1, w_2, w_3),\frac{\partial}{\partial w_3}J(w_1, w_2, w_3) \end{pmatrix}$$
Optimization without Gradients¶
First let's use common-sense and grit to optimize our network.
Start with random weights. Compute the Empirical Loss for the data.
Then pick one weight and try increasing it a tiny bit and see how the prediction changes using training data. Similarly try decreasing it a tiny bit. Compute the Empirical Loss in each case.
Update the weight in the direction that reduces the Empirical Loss.
Repeat this procedure for each of the weights.
And repeat the whole process multiple times to continue improving the prediction.
Gradient Descent¶
Our "commonsense" approach was to test update $w_i + c$ and $w_i - c$ for some tiny step $c$ and use the best one:
$$ w_i \rightarrow w_i + c \rightarrow L'$$ $$ w_i \rightarrow w_i - c \rightarrow L''$$
Calculus tells us the best update in one analytical calculation (no need to test it):
$$ w_i \rightarrow w_i - \mu \frac{\partial}{\partial w_i}L(f(w_1, w_2, w_3))$$
Where we again have to pick a step size $\mu$.
In vector notation:
$$ \mathbf w \rightarrow \mathbf w - \mu \nabla L$$
Benefits of using calculus¶
How much computation is needed using the gradient-free approach if there are $n$ weights?
How much computation is needed using the gradient?
Numeric differentiation¶
Here, we compute an approxiation of the gradients using the equation: $\dfrac{\partial f}{\partial x} = \displaystyle{\lim_{\epsilon \to 0}}\dfrac{f(x+\epsilon, y) - f(x, y)}{\epsilon}$ (and there is a similar definition for $\dfrac{\partial f}{\partial y}$).
def gradients(func, vars_list, eps=0.0001):
partial_derivatives = []
base_func_eval = func(*vars_list)
for idx in range(len(vars_list)):
tweaked_vars = vars_list[:]
tweaked_vars[idx] += eps
tweaked_func_eval = func(*tweaked_vars)
derivative = (tweaked_func_eval - base_func_eval) / eps
partial_derivatives.append(derivative)
return partial_derivatives
def df(x, y):
return gradients(f, [x, y])
df(3, 4)
def dfdx(x, y):
return gradients(f, [x,y])[0]
def dfdy(x, y):
return gradients(f, [x,y])[1]
dfdx(3., 4.), dfdy(3., 4.)
Now we can simply apply the gradients() function to these functions:
def d2f(x, y):
return [gradients(dfdx, [3., 4.]), gradients(dfdy, [3., 4.])]
d2f(3, 4)
II. Gradient Descent¶
Gradient Descent - improvements (or sometimes not...)¶
Stochastic
Batch Stochastic
Momentum
Acceleration
Adaptive step sizes
Averaging of steps
Parallelizing the Gradient Computation¶
$$ \mathbf w \rightarrow \mathbf w - \mu \nabla L_{emp}(f) $$
$$ L_{emp}(f) = \frac{1}{m}\sum_{i=1}^m L\big(f(\mathbf x_{(i)}), y_i\big) $$
The gradient of the sum is the sum of gradients \begin{align} \nabla L_{emp}(f) &= \nabla \frac{1}{m}\sum_{i=1}^m L\big(f(\mathbf x_{(i)}), y_i\big) \\ &= \frac{1}{m}\sum_{i=1}^m \nabla L\big(f(\mathbf x_{(i)}), y_i\big) \end{align} Each can be computed independently of all others
"Embarrasingly Parallel"¶
Each can be computed independently of all others, trivial to parallelize. $$ \mathbf w \rightarrow \mathbf w + \eta \nabla L_{emp}(f) $$
\begin{align} \mathbf w \rightarrow \mathbf w + \eta \frac{1}{m} \nabla L\big(f(\mathbf x_{(1)}), y_1\big) \\ \mathbf w \rightarrow \mathbf w + \eta \frac{1}{m} \nabla L\big(f(\mathbf x_{(2)}), y_2\big) \\ \mathbf w \rightarrow \mathbf w + \eta \frac{1}{m} \nabla L\big(f(\mathbf x_{(3)}), y_3\big) \\ ... \end{align}
Apply & Prove this for a small problem with L2 loss.
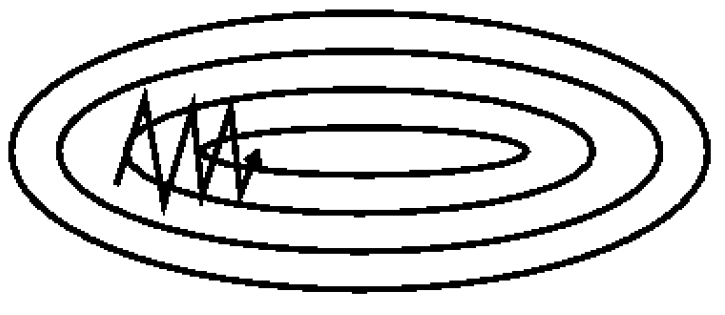
Stochastic Gradient Descent¶
\begin{align} \nabla L_{emp}(f) &= \nabla \frac{1}{m}\sum_{i=1}^m L\big(f(\mathbf x_{(i)}), y_i\big) = \frac{1}{m}\sum_{i=1}^m \nabla L\big(f(\mathbf x_{(i)}), y_i\big) \\ &\rightarrow \frac{1}{m} \nabla L\big(f(\mathbf x_{(i)}), y_i\big) \end{align}
- Randomly choose sample $i$.
- Compute $\nabla L$ gradient of Loss using only sample $i$
- Update weights $\mathbf w \rightarrow \mathbf w - \mu \nabla L$
- Repeat
Descent direction fluctuates a lot more (can be a good thing):
Batch Stochastic Gradient Descent¶
Considered one of the key reasons for Deep Learning's success
- Instead of single sample, use small subsets of the training data ("batches") to compute a step.
$$ \nabla L_{emp}(f) = \nabla \frac{1}{m}\sum_{i=1}^m L\big(f(\mathbf x_{(i)}), y_i\big) \rightarrow \frac{1}{m_{batch}}\sum_{i\in B_k} \nabla L\big(f(\mathbf x_{(i)}), y_i\big) $$
With single-sample steps, gradient is noisy (jumps around a lot). Using a larger batch smooths this out, but some degree of noisiness is believed to be valuable in getting out of local minima or saddle points.
Batch-size trades off this effect.
Epoch = single pass through the entire dataset in batch steps.
Batch Stochastic Gradient Descent (cont)¶
$$ \nabla L_{emp}(f) = \nabla \frac{1}{m}\sum_{i=1}^m L\big(f(\mathbf x_{(i)}), y_i\big) \rightarrow \frac{1}{m_{batch}}\sum_{i\in B_k} \nabla L\big(f(\mathbf x_{(i)}), y_i\big) $$
- Randomly choose batch of samples $B = \{i_1,i_2, ...\}$ of size 8 to 128 (or whatever).
- Compute $\nabla L$ gradient of Loss using batch of samples
- Update weights $\mathbf w \rightarrow \mathbf w - \mu \nabla L$
- Repeat
Momentum¶
Accumulates corrections so same directions build while "zig-zags" cancel out.
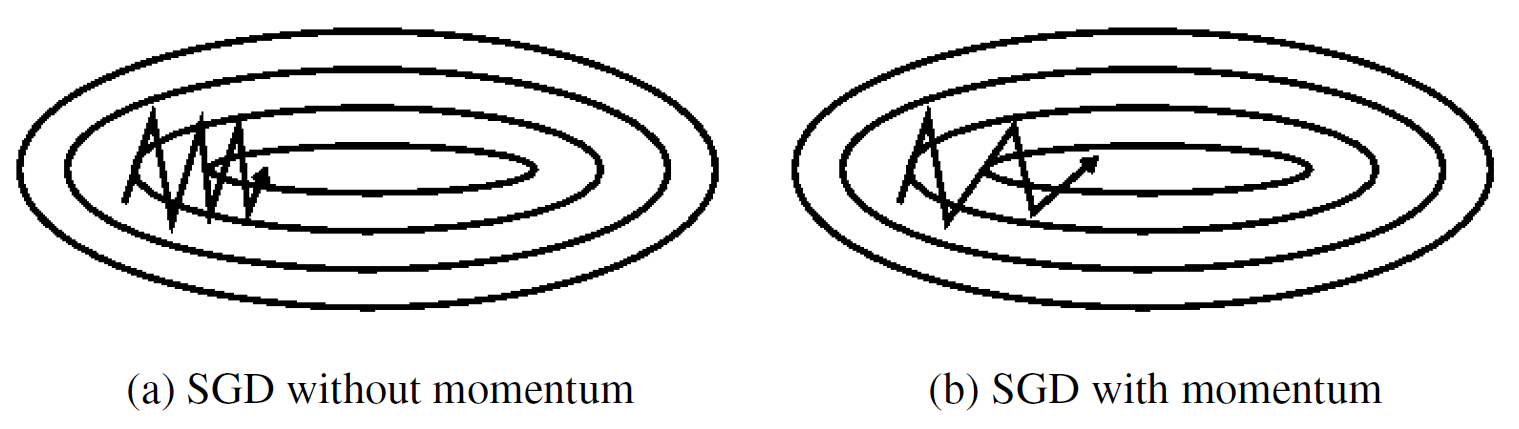
\begin{align} \mathbf v^{(k+1)} &= \gamma \mathbf v^{(k)} + \eta \nabla J(\mathbf w^{(k)}) \\ \mathbf w^{(k+1)} &= \mathbf w^{(k)} - \mathbf v^{(k+1)} \end{align}
\begin{align} \mathbf v &\rightarrow \gamma \mathbf v + \eta \nabla J(\mathbf w) \\ \mathbf w &\rightarrow \mathbf w - \mathbf v \end{align}
Typically $\gamma=0.9$.
Acceleration (Nesterov Accelerated Gradient - NAG)¶
Momentum that uses future value of gradient
\begin{align} \mathbf v &\rightarrow \gamma \mathbf v + \eta \nabla J(\mathbf w - \gamma \mathbf v) \\ \mathbf w &\rightarrow \mathbf w - \mathbf v \end{align}
- "slows down" when nearing bottom.
Adagrad¶
Adaptive gradient: accelerate each weight differently by accumulating their squares
\begin{align} w_i &\rightarrow w_i - \frac{1}{\sqrt{G_i+\epsilon}}[\nabla J(\mathbf w)]_i \\ G_i &\rightarrow G_i + [\nabla J(\mathbf w)]_i^2 \end{align}
- No learning rate needed.
- Problem: scale factor gets monotonically larger $\rightarrow$ optimizing crawls to stop.
Adaptive Moment Estimation ~ Adam¶
Diederik P. Kingma, Jimmy Ba, "Adam: A Method for Stochastic Optimization", ICLR 2015, https://arxiv.org/abs/1412.6980
"Windowed" average of gradients and gradients squared. \begin{align} \mathbf m &\rightarrow \beta_1 \mathbf m + (1-\beta_1) \nabla J(\mathbf w) \\ v &\rightarrow \beta_2 v + (1-\beta_2) ||\nabla J(\mathbf w)||_2^2 \end{align} "Bias correction" for step $k$ due to initial momentum being zero \begin{align} \hat{\mathbf m} &= \frac{1}{1-\beta_1^k} \mathbf m \\ \hat{ v} &= \frac{1}{1-\beta_2^k} v \end{align} \begin{align} \mathbf w &\rightarrow \mathbf w - \frac{1}{\sqrt{\hat{v}}+\epsilon}\hat{\mathbf m} \end{align}
Summary so far...¶
- Compute the gradient of the Loss w.r.t. the weights
- Use gradient to compute adjustment to add to the weights
Backpropagation¶
For a deep network the calculation of the gradients can itself be a massive task, unless we are smart about it.
The idea of backpropagation is basically to re-use calculations from the forward computation (where we computed output of network given input sample).
Simple case of deeper class of methods for performing calculations over graphs.
(Overly) Simple Example¶
https://www.youtube.com/watch?v=q0pm3BrIUFo
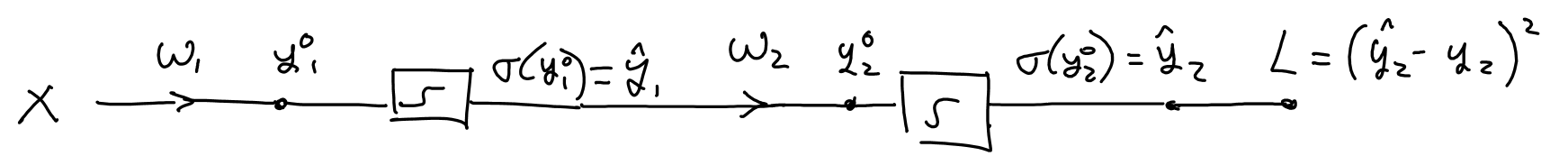
- Add the loss calculation to the end of the network.
- Forward pass - calculate values at each point
- Backward pass - use values to compute gradient w.r.t. each weight
Note backward pass is a single pass, since many computations are shared
III. Autodiff¶
Example
$$f(x,y) = x^2y+y+2$$
Optimization goal: find $x$ and $y$ that maximizes or minimizes $f(x,y)$
What is the comparable equation for a Neural Network?
Gradient descent¶
- start from initial guess at $(x_0,y_0)$
- Compute gradient $\nabla f(x_0,y_0) = \left(\frac{\partial f}{\partial x},\frac{\partial f}{\partial y}\right)|_{x_0,y_0}$
- Adjust point $(x_1,y_1) = (x_0,y_0) - \eta \nabla f(x_0,y_0)$
- compute gradient $\nabla f(x_1,y_1)$ ...
Differentiation rules¶
- The derivative of a constant is 0.
- The derivative of $λx$ is $λ$ (where $λ$ is a constant).
- The derivative of $x^λ$ is $λx^{λ – 1}$, so the derivative of $x^2$ is $2x$.
- The derivative of a sum of functions is the sum of these functions’ derivatives.
- The derivative of $λ$ times a function is $λ$ times its derivative.
Symbolic Differentiation¶
- Key to scalability is automated calculation of derivatives
- Manual calculation and coding of derivatives gets very messy and error-prone.
- Deep networks mean tons of such calculations
Derivative of computational graph¶
From computational graph of function we can form computational graph of partial derivative of function
$$g(x,y) = 5 + xy$$ $$\frac{\partial g}{\partial x} = 0 + (0 \times x + y \times 1)$$
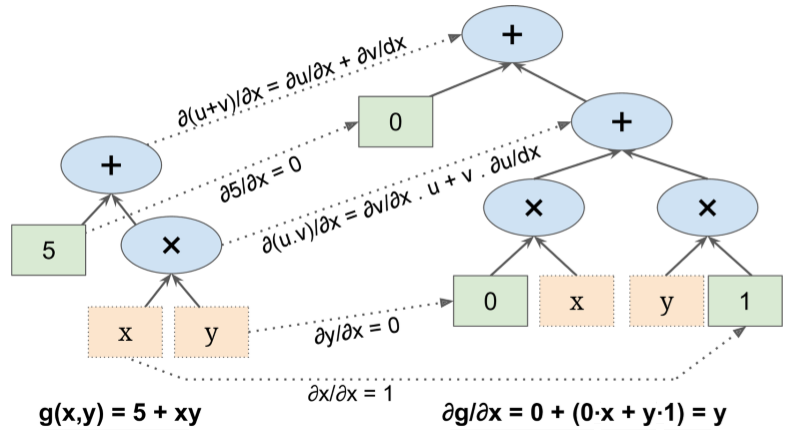
- Start by taking partial derivatives of leaf nodes
- Move up to next node and write graph for derivative of multiplication
- Move up to final node and write graph for derivative of addition
Notice the similarity of the graphs
Methods to automatically compute gradients¶
Numerical differentiation¶
Some functions cannot be broken down into fundamental ops
Approximate derivative with finite difference
$$ \frac{\partial f(x)}{\partial x} = \lim_{\epsilon\rightarrow 0}\frac{f(x+\epsilon,y)-f(x,y)}{\epsilon} \approx \frac{f(x+\epsilon,y)-f(x,y)}{\epsilon} $$
def f(x, y):
return x**2*y + y + 2
def derivative(f, x, y, x_eps, y_eps):
return (f(x + x_eps, y + y_eps) - f(x, y)) / (x_eps + y_eps)
df_dx = derivative(f, 3, 4, 0.00001, 0)
df_dy = derivative(f, 3, 4, 0, 0.00001)
print(df_dx)
print(df_dy)
True answers should be 24 and 10
Less efficient than symbolic gradient due to need for many calls to to function
Handy since easy way to test your gradient implementation.
Forward-Mode Autodiff¶
- Neither numerical differentiation nor symbolic differentiation
- Uses dual numbers - numbers of the form $a + b \epsilon$
- $a$ and $b$ are real numbers
- $\epsilon$ is an infinitesimal number such that $\epsilon^2 = 0$ (but $\epsilon \ne 0$)
- Represented in memory as a pair of floats. For example, $42 + 24 \epsilon$ is represented by the pair (42.0, 24.0).
A few operations with dual numbers
- $λ a+b\epsilon = λa+λb\epsilon$
- $a+b\epsilon + c+d\epsilon = a+c + b+d \epsilon$
- $(a+b\epsilon) × (c+d\epsilon) = ac+ (ad+bc) \epsilon+ bd \epsilon^2 = ac+ (ad+bc) \epsilon$
Dual numbers have their own arithmetic rules, which are generally quite natural. For example:
Addition
$(a_1 + b_1\epsilon) + (a_2 + b_2\epsilon) = (a_1 + a_2) + (b_1 + b_2)\epsilon$
Subtraction
$(a_1 + b_1\epsilon) - (a_2 + b_2\epsilon) = (a_1 - a_2) + (b_1 - b_2)\epsilon$
Multiplication
$(a_1 + b_1\epsilon) \times (a_2 + b_2\epsilon) = (a_1 a_2) + (a_1 b_2 + a_2 b_1)\epsilon + b_1 b_2\epsilon^2 = (a_1 a_2) + (a_1b_2 + a_2b_1)\epsilon$
Division
$\dfrac{a_1 + b_1\epsilon}{a_2 + b_2\epsilon} = \dfrac{a_1 + b_1\epsilon}{a_2 + b_2\epsilon} \cdot \dfrac{a_2 - b_2\epsilon}{a_2 - b_2\epsilon} = \dfrac{a_1 a_2 + (b_1 a_2 - a_1 b_2)\epsilon - b_1 b_2\epsilon^2}{{a_2}^2 + (a_2 b_2 - a_2 b_2)\epsilon - {b_2}^2\epsilon} = \dfrac{a_1}{a_2} + \dfrac{a_1 b_2 - b_1 a_2}{{a_2}^2}\epsilon$
Power
$(a + b\epsilon)^n = a^n + (n a^{n-1}b)\epsilon$
etc.
Key fact:¶
$$h(a + b \epsilon ) = h(a) + b × h′(a) \epsilon$$
I.e. the input is the pair $(a,b)$ and the output is the pair $(h(a), b × h′(a))$
Get function evaluation and derivative together in a forward computation through the computational graph
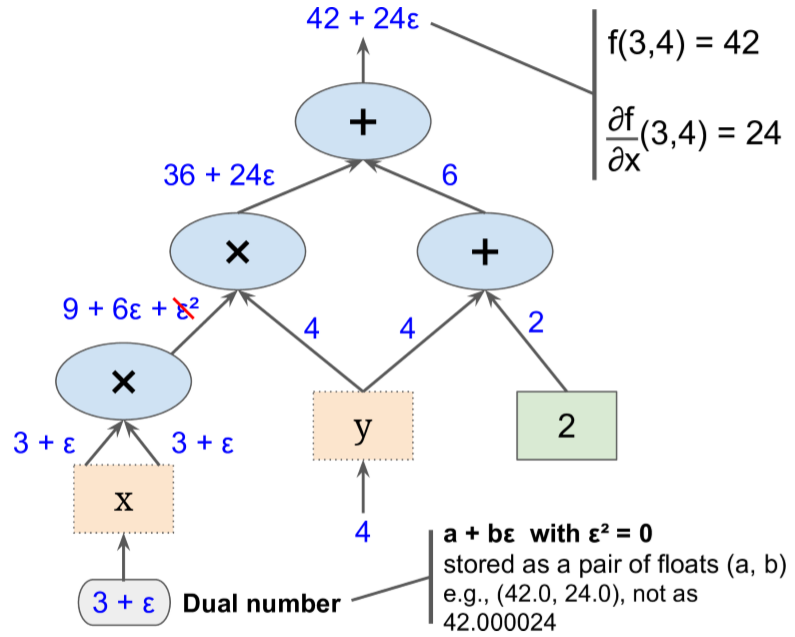
class DualNumber(object):
def __init__(self, value=0.0, eps=0.0):
self.value = value
self.eps = eps
def __add__(self, b):
return DualNumber(self.value + self.to_dual(b).value,
self.eps + self.to_dual(b).eps)
def __radd__(self, a):
return self.to_dual(a).__add__(self)
def __mul__(self, b):
return DualNumber(self.value * self.to_dual(b).value,
self.eps * self.to_dual(b).value + self.value * self.to_dual(b).eps)
def __rmul__(self, a):
return self.to_dual(a).__mul__(self)
def __str__(self):
if self.eps:
return "{:.1f} + {:.1f}ε".format(self.value, self.eps)
else:
return "{:.1f}".format(self.value)
def __repr__(self):
return str(self)
@classmethod
def to_dual(cls, n):
if hasattr(n, "value"):
return n
else:
return cls(n)
$3 + (3 + 4 \epsilon) = 6 + 4\epsilon$
3 + DualNumber(3, 4)
$(3 + 4ε)\times(5 + 7ε)$ = $3 \times 5 + 3 \times 7ε + 4ε \times 5 + 4ε \times 7ε$ = $15 + 21ε + 20ε + 28ε^2$ = $15 + 41ε + 28 \times 0$ = $15 + 41ε$
DualNumber(3, 4) * DualNumber(5, 7)
Now use to differentiate $f$¶
x.value = DualNumber(3.0)
y.value = DualNumber(4.0)
f.evaluate()
x.value = DualNumber(3.0, 1.0) # 3 + ε
y.value = DualNumber(4.0) # 4
dfdx = f.evaluate().eps
x.value = DualNumber(3.0) # 3
y.value = DualNumber(4.0, 1.0) # 4 + ε
dfdy = f.evaluate().eps
dfdx
dfdy
Drawback of Forward mode Autodiff¶
still need to repeat computational graph pass for every variable
- $f(x,y)$ - two times
- $f(w_1, w_2, ..., w_n, b)$ - $n+1$ times
Reverse-mode Autodiff, a.k.a. Backpropagation¶
Two passes:
- It first goes through the graph in the forward direction (i.e., from the inputs to the output) to compute the value of each node.
- Then it goes in the reverse direction (i.e., from the output to the inputs) to compute all the partial derivatives.
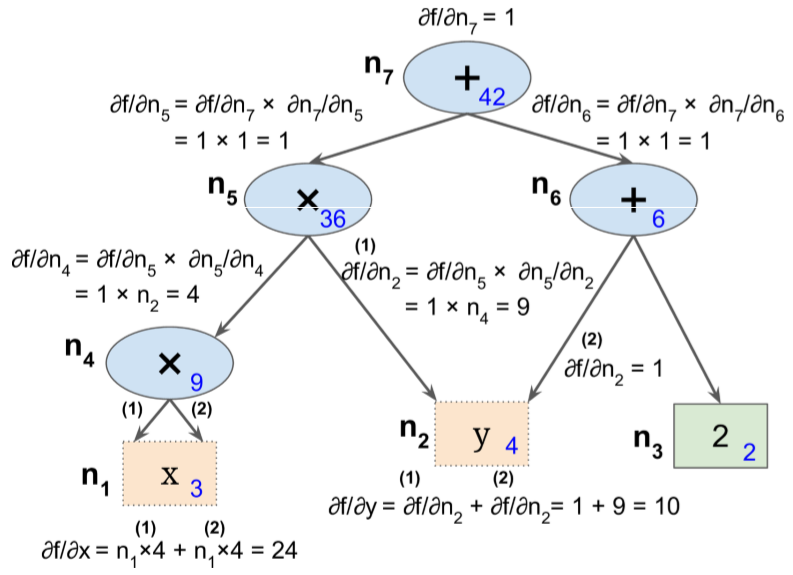
- The computational graph is a hierarchical implementation of the function in fundamental parts
- The derivaive of the function can follow the same hierarchy using the chain rule
$$\frac{\partial f}{\partial x} = \frac{\partial f}{\partial n_i} \frac{\partial n_i}{\partial x}$$
where $n_i$ is the $i$th node
- $n_7 = f$ so $\frac{\partial f}{\partial n_7} = 1$
- $\frac{\partial f}{\partial n_5} = \frac{\partial f}{\partial n_7} \frac{\partial n_7}{\partial n_5}$
- $n_7 = n_5+n_6$ so $\frac{\partial n_7}{\partial n_5} = 1$ and hence $\frac{\partial f}{\partial n_5} = 1 \times 1 = 1$
- $\frac{\partial f}{\partial n_4} = \frac{\partial f}{\partial n_5} \frac{\partial n_5}{\partial n_4}$
- $n_5 = n_4 n_2$ so $\frac{\partial n_5}{\partial n_4} = n_2$ and hence $\frac{\partial f}{\partial n_4} = 1 \times n_2 =4$
The process continues until we reach the bottom of the graph. At that point we will have calculated all the partial derivatives of $f(x,y)$ at the point $x = 3$ and $y = 4$. In this example, we find $∂f/∂x = 24$ and $∂f/∂y = 10$.
Adding functions¶
To implement new function in autodiff solver like TF, simply need to provide its derivative function in terms of elementary ops.
class Const(object):
def __init__(self, value):
self.value = value
def evaluate(self):
return self.value
def backpropagate(self, gradient):
pass
def __str__(self):
return str(self.value)
class Var(object):
def __init__(self, name, init_value=0):
self.value = init_value
self.name = name
self.gradient = 0
def evaluate(self):
return self.value
def backpropagate(self, gradient):
self.gradient += gradient
def __str__(self):
return self.name
class BinaryOperator(object):
def __init__(self, a, b):
self.a = a
self.b = b
class Add(BinaryOperator):
def evaluate(self):
self.value = self.a.evaluate() + self.b.evaluate()
return self.value
def backpropagate(self, gradient):
self.a.backpropagate(gradient)
self.b.backpropagate(gradient)
def __str__(self):
return "{} + {}".format(self.a, self.b)
class Mul(BinaryOperator):
def evaluate(self):
self.value = self.a.evaluate() * self.b.evaluate()
return self.value
def backpropagate(self, gradient):
self.a.backpropagate(gradient * self.b.value)
self.b.backpropagate(gradient * self.a.value)
def __str__(self):
return "({}) * ({})".format(self.a, self.b)
x = Var("x", init_value=3)
y = Var("y", init_value=4)
f = Add(Mul(Mul(x, x), y), Add(y, Const(2))) # f(x,y) = x²y + y + 2
result = f.evaluate()
f.backpropagate(1.0)
print(f)
result
x.gradient
y.gradient
in this implementation the outputs are just numbers, not symbolic expressions,
so we are limited to first order derivatives.
Could have made the
backpropagate()methods return symbolic expressions rather than values (e.g., returnAdd(2,3)rather than 5).This would make it possible to compute second order gradients (and beyond). This is what TensorFlow does, as do all the major libraries that implement autodiff.
(Overly) Simple Example Again¶
- Add the loss calculation to the end of the network.
- Forward pass - calculate values at each point
- Backward pass - use values to compute gradient w.r.t. each weight
Note backward pass is a single pass, since many computations are shared